
Introduction
Road incidents are one of the leading causes of death worldwide. Automobile companies constantly try to innovate their safety mechanisms to minimize the risk of such injuries and fatalities. Often these focus on mitigating damage once an accident has already occurred, such as improved air bags. However, it is also important to analyze the factors that go into causing fatal accidents such as driver behavior, environment, etc. The goal of this project is to identify the components that are reliable predictors of accidents and use them to predict injury level.
The data set used in this analysis comes from the Fatality Analysis Reporting System (FARS) run by the National Highway Traffic Saftey Administration (NHTSA). The data is collected on crashes that occur throughout the US and includes all crashes resulting in injury or fatality in 2018.
Data Set
The full data set includes a wealth of information on outcomes for each vehicle and person involved in the crash, as well as a number of variables relating to the crash and the emergency response. In total, it includes over 80,000 data points representing persons involved in the crash and 61 input features. The features range from type of road to collision orientation and many others. The outcome for each individual has 5 possible levels of injury: "No Apparent Injury", "Possible Injury", "Suspected Minor Injury", "Suspected Serious Injury", and "Fatal Injury". We hope to perform an analysis on the features present in the data and determine factors that are the most likely to predict this level of injury.
Data Formatting
Factors that occured after the crash, such as emergency response time and time of death were ignored. This decision was made in part because it would be trivial to determine the injury level with features such as whether or not the person was taken to the hospital or the time of death. This also does not help accomplish the goal of detemrining how to improve safety precautions in vehicles, so we excluded all features that occured as a result of the crash. This reduced the number of features to 17 and when incomplete data was trimmed from the set the final data had approximately 60,000 data points. The final change was grouping injury severity into 3 outcomes: "No Injury", "Injury", and "Fatality" as five categories would lead to poor prediction accuracy.
Analysis Methods
Preliminary data analysis focused on choosing the relevant factors to remove extraneous factors and to improve runtime of model training. Unsupervised methods used included using mutual information to select the most relevant columns of data. Catagorical factors were expanded with binary dummy variables to allow for inclusion of all possible factors, so PCA was also applied to reduce dimensionality and speed up model training since the majority of feature were categorical. Supervised learning methods were used on the final data set to predict the injury level of people in the test data set. Methods tested include decision trees, neural networks, SVM, and random forests to classify each person by injury level.
Mutual Information Analysis
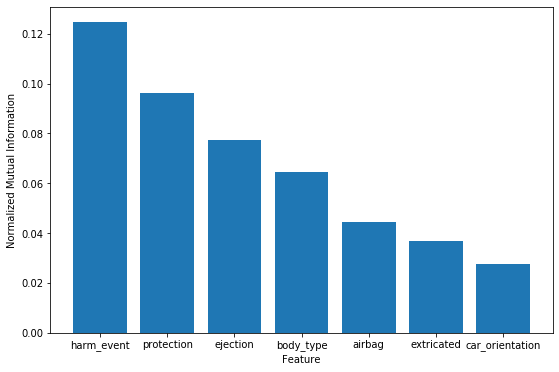
The above plot shows the normalized mutual information between each of the dataset features and the injury severity. The top 7 features are pictured out of 16 tested. This shows that the 3 best features for determining the injury level are the first harmful event in a crash, the use of protection by the person, and whether the person was fully or partially ejected from a vehicle. This suggests that in order to prevent injury in crashes focus should be placed on making sure that all passengers are using appropriate protection, and in ensuring redesigning vehicles to ensure that occupants are not ejected.
Output vs High Information Feature
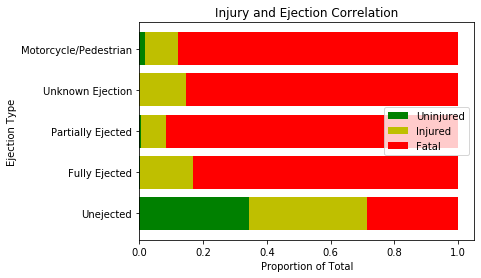
The above chart shows the relationship between injury severity and a feature that has high mutual information. There is a lot of distinction in outcomes between being ejected and not being ejected.
Output vs Low Information Feature

This chart shows the relationship between injuries and a low mutual information feature. It is evident that the proportions are much more similar than a high information feature.
Conclusions
Each model was trained and tested using 5 fold cross validation to assess effectiveness at predicting injury level of a person. With 3 injury levels the highest prediction accuracy was 72% using linear SVM with the a K value of 16. A K value of 12 is considered to be optimal in this case, as there is very little increase in any performance metrics with higher K values, while model training time increases substantially. At this value prediction accuracy, precision, recall and F1-score are all 0.71. Each model was tested with a number of different parameteres to determine the best set, as described below. Given the large number of factors that involved in a crash and the level of randomness in how injuries occur, these levels of prediction accuracy are considered high.
Confusion Matrix
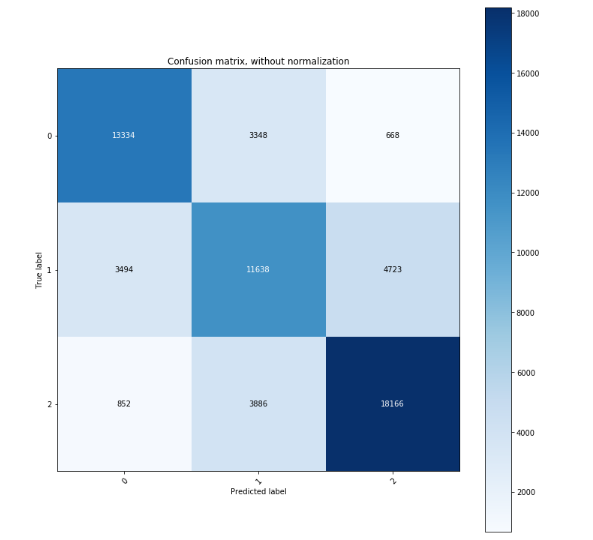
The confusion matrix shows the ability of our model to predict the correct injury level of a person involved in a crash.
Influence of K Values of Model
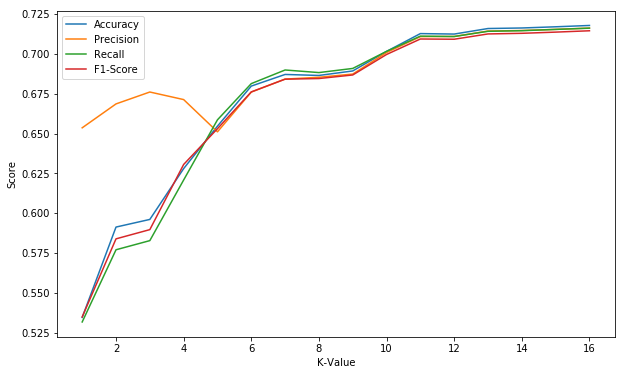
The above chart shows the influence of K values on the model.
References
- Chunjiao Dong, Chunfu Shao, Juan Li, and Zhihua Xiong, “An Improved Deep Learning Model for Traffic Crash Prediction,” Journal of Advanced Transportation, vol. 2018, Article ID 3869106, 13 pages, 2018. https://doi.org/10.1155/2018/3869106.
- F. L. Mannering and C. R. Bhat, “Analytic methods in accident research: methodological frontier and future directions,” Analytic Methods in Accident Research, vol. 1, pp. 1–22, 2014.
- Chong, Miao & Abraham, Ajith & Paprzycki, Marcin. (2005). Traffic Accident Analysis Using Machine Learning Paradigms.. Informatica (Slovenia). 29. 89-98.
- Doquire, G. & Verleysen, Michel. (2011). An hybrid approach to feature selection for mixed categorical and continuous data. KDIR 2011 - Proceedings of the International Conference on Knowledge Discovery and Information Retrieval. 394-401.